Image recognition pomocí ML.NET
19.11.2020Slovník
| AI | Artificial intelligence neboli umělá inteligence. |
| Machine learning | Strojové učení: princip je zhruba takový, že algoritmus se zlepšuje v konkrétní úloze, čím více má k dispozici dat. Současně se s tímto pojmem skloňuje i cloud computing, kdy může firma outsourcovat výpočetní výkon do cloudu na dobu nezbytně potřebnou, například pro účely trénování AI modelu. |
Obsah
ML proces
Pokud jsme se rozhodli, že chceme použít ML, potřebujeme data. Ty buď již máme, nebo je musíme získat. Data poté upravíme do podoby, aby jim rozuměl ML algoritmus, kterého chceme použít. Data lze rozdělit na dvě části, přičemž jedna část bude sloužit pro trénování a druhá část pro otestování modelu. Alternativně je možné použít techniku cross-validation, která data také rozdělí na dvě části, ale kontrola probíhá v iteracích, kdy se dataset pokaždé rozdělí jiným způsobem. Jakmile máme model vytrénovaný na požadovanou úroveň, můžeme ho použít. Variantou je také nechat model, aby se postupně přetrénovával, jak nám data přibývají.
Příprava dat
Jako úlohu jsem zvolil rozpoznávání obrázků, tudíž si nějaké obrázky musíme obstarat. K tomu můžeme použít webového crawlera icrawler, který je napsaný v Pythonu a umožňuje nám stahovat obrázky ze znamých vyhledávačů jako je Google nebo Bing.
Stáhnutí obrázků
Ke kočce, psovi i lvovi stáhneme postupně 100 obrázků z vyhledávače Bing do následující adresářové struktury.
- images
- cat
- dog
- lion
from icrawler.builtin import BingImageCrawler
crawler = BingImageCrawler(storage={'root_dir': 'C:\images\cat'})
crawler.crawl(keyword='cat', max_num=100)
crawler = BingImageCrawler(storage={'root_dir': 'C:\images\dog'})
crawler.crawl(keyword='dog', max_num=100)
crawler = BingImageCrawler(storage={'root_dir': 'C:\images\lion'})
crawler.crawl(keyword='lion', max_num=100)Vygenerujeme tsv (table separated values) soubor bez hlavičky, který ML algoritmus již umí načíst. K tomu si připravíme následující statickou metodu.
public static void CreateTsvFileSource(string rootImageDirectory, string outputFilePath)
{
// Get collection of sub-directories
var directories = Directory.EnumerateDirectories(rootImageDirectory);
// Overwrite existing file, if exists, with new TSV file.
using (FileStream fs = new FileStream(outputFilePath, FileMode.Create, FileAccess.Write))
using (StreamWriter sw = new StreamWriter(fs))
{
// Foreach directories with images
foreach (string directory in directories)
{
// Directory name is considered as classification label.
string label = $"{directory.Substring(directory.LastIndexOf(Path.DirectorySeparatorChar) + 1)}";
// Foreach directory images and save the label
// and the image path to the TSV file.
var files = Directory.EnumerateFiles(directory);
foreach (string filePath in files)
{
sw.WriteLine($"{label}\t{filePath}");
}
}
}
}Metodu snadno zavoláme a nastavíme cestu s obrázky a cestu kam se má tsv soubor vytvořit.
CreateTsvFileSource("C:\images", "C:\datasource.tsv");datasource.tsv vypadá následovně
cat C:\images\cat\000001.jpg
cat C:\images\cat\000002.jpg
...
dog C:\images\dog\000001.jpg
dog C:\images\dog\000002.jpg
...
lion C:\images\lion\000001.jpg
lion C:\images\lion\000002.jpgVytvoření modelu
Pro vytvoření modelu si vytvoříme třídu, která bude mít jedinou metodu CreateModel a bude obsahovat 5 částí
- 1. Načtení informací z datasource.tsv souboru.
- 2. Nastavení algoritmu.
- 3. Otestování modelu pomocí cross-validation techniky a zobrazení kontrolních metrik.
- 4. Spuštění trénování
- 5. Uložení modelu
Vycházel jsem z kódu, který mi vygeneroval ML.NET Wizard a který jsem si trochu upravil a zjednodušil. Vytvoříme si 3 třídy ModelBuilder, ModelInput a ModelOutput.
ModelBuilder.cs
using Microsoft.ML;
using Microsoft.ML.Vision;
using System;
using System.Linq;
namespace ImageRecognition
{
public class ModelBuilder
{
private readonly MLContext mlContext;
private readonly MulticlassClassificationMetricsCalculator metricsCalculator;
public ModelBuilder()
{
mlContext = new MLContext(seed: 1);
metricsCalculator = new MulticlassClassificationMetricsCalculator();
}
/// <summary>
/// Will import and transform data, execute training algorithm and save the model.
/// </summary>
/// <param name="datasource">Full file path to the .tsv file,
/// which will be used for model training (in MS examples often called as TRAIN_DATA_FILEPATH).
/// </param>
/// /// <param name="output">Full file path where the model in .zip format will be saved
/// (in MS examples often called as MODEL_FILEPATH).
/// </param>
public void CreateModel(string datasource, string output)
{
// 1. Lazy data import
Console.WriteLine("Executing step 1.");
IDataView trainingDataView
= mlContext.Data.LoadFromTextFile<ModelInput>(
path: datasource,
hasHeader: true,
separatorChar: '\t',
allowQuoting: true,
allowSparse: false);
// 2. Build training pipeline (prepare data and select algorithm to train)
Console.WriteLine("Executing step 2.");
var pipeline
= mlContext.Transforms.Conversion.MapValueToKey("Label", "Label")
.Append(mlContext.Transforms.LoadRawImageBytes("ImageSource_featurized", null, "ImageSource"))
.Append(mlContext.Transforms.CopyColumns("Features", "ImageSource_featurized"));
var trainer
= mlContext.MulticlassClassification.Trainers
.ImageClassification(new ImageClassificationTrainer.Options()
{ LabelColumnName = "Label", FeatureColumnName = "Features" })
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel", "PredictedLabel"));
var trainingPipeline = pipeline.Append(trainer);
// 3. Evaluate quality of model with cross validation technique and display performance metrics.
Console.WriteLine("Executing step 3.");
var performance
= mlContext.MulticlassClassification
.CrossValidate(trainingDataView, trainingPipeline, numberOfFolds: 5, labelColumnName: "Label");
metricsCalculator.Print(performance);
// 4. Execute training
Console.WriteLine("Executing step 4.");
ITransformer model = trainingPipeline.Fit(trainingDataView);
// 5. Save model
Console.WriteLine("Executing step 5.");
mlContext.Model.Save(model, trainingDataView.Schema, output);
Console.WriteLine("Model saved. Hit any key to finish.");
Console.ReadLine();
}
}
}// This file was auto-generated by ML.NET Model Builder.
using Microsoft.ML.Data;
namespace ImageRecognition
{
public class ModelInput
{
[ColumnName("Label"), LoadColumn(0)]
public string Label { get; set; }
[ColumnName("ImageSource"), LoadColumn(1)]
public string ImageSource { get; set; }
}
}// This file was auto-generated by ML.NET Model Builder.
using System;
using Microsoft.ML.Data;
namespace ImageRecognition
{
public class ModelOutput
{
// ColumnName attribute is used to change the column name from
// its default value, which is the name of the field.
[ColumnName("PredictedLabel")]
public String Prediction { get; set; }
public float[] Score { get; set; }
}
}Abychom mohli v kroku 3 zobrazit metriky, třída má závislost na další třídu MulticlassClassificationMetricsCalculator kterou také musíme vytvořit a přidat do projektu.
MulticlassClassificationMetricsCalculator.csusing Microsoft.ML;
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Linq;
namespace ImageRecognition
{
class MulticlassClassificationMetricsCalculator
{
public void Print(IEnumerable<TrainCatalogBase.CrossValidationResult<MulticlassClassificationMetrics>> crossValResults)
{
var metricsInMultipleFolds = crossValResults.Select(r => r.Metrics);
var microAccuracyValues = metricsInMultipleFolds.Select(m => m.MicroAccuracy);
var microAccuracyAverage = microAccuracyValues.Average();
var microAccuraciesStdDeviation = CalculateStandardDeviation(microAccuracyValues);
var microAccuraciesConfidenceInterval95 = CalculateConfidenceInterval95(microAccuracyValues);
var macroAccuracyValues = metricsInMultipleFolds.Select(m => m.MacroAccuracy);
var macroAccuracyAverage = macroAccuracyValues.Average();
var macroAccuraciesStdDeviation = CalculateStandardDeviation(macroAccuracyValues);
var macroAccuraciesConfidenceInterval95 = CalculateConfidenceInterval95(macroAccuracyValues);
var logLossValues = metricsInMultipleFolds.Select(m => m.LogLoss);
var logLossAverage = logLossValues.Average();
var logLossStdDeviation = CalculateStandardDeviation(logLossValues);
var logLossConfidenceInterval95 = CalculateConfidenceInterval95(logLossValues);
var logLossReductionValues = metricsInMultipleFolds.Select(m => m.LogLossReduction);
var logLossReductionAverage = logLossReductionValues.Average();
var logLossReductionStdDeviation = CalculateStandardDeviation(logLossReductionValues);
var logLossReductionConfidenceInterval95 = CalculateConfidenceInterval95(logLossReductionValues);
Console.WriteLine($"*************************************************************************************************************");
Console.WriteLine($"* Metrics for Multi-class Classification model ");
Console.WriteLine($"*------------------------------------------------------------------------------------------------------------");
Console.WriteLine($"* Accuracy is a value between 0 and 1, the closer to 1, the better. ");
Console.WriteLine($"* LogLoss, the closer the value is to 0, the better. ");
Console.WriteLine($"*------------------------------------------------------------------------------------------------------------");
Console.WriteLine($"* Average MicroAccuracy: {microAccuracyAverage:0.###} - Standard deviation: ({microAccuraciesStdDeviation:#.###}) - Confidence Interval 95%: ({microAccuraciesConfidenceInterval95:#.###})");
Console.WriteLine($"* Average MacroAccuracy: {macroAccuracyAverage:0.###} - Standard deviation: ({macroAccuraciesStdDeviation:#.###}) - Confidence Interval 95%: ({macroAccuraciesConfidenceInterval95:#.###})");
Console.WriteLine($"* Average LogLoss: {logLossAverage:#.###} - Standard deviation: ({logLossStdDeviation:#.###}) - Confidence Interval 95%: ({logLossConfidenceInterval95:#.###})");
Console.WriteLine($"* Average LogLossReduction: {logLossReductionAverage:#.###} - Standard deviation: ({logLossReductionStdDeviation:#.###}) - Confidence Interval 95%: ({logLossReductionConfidenceInterval95:#.###})");
Console.WriteLine($"*************************************************************************************************************");
}
public double CalculateStandardDeviation(IEnumerable<double> values)
{
double average = values.Average();
double sumOfSquaresOfDifferences = values.Select(val => (val - average) * (val - average)).Sum();
double standardDeviation = Math.Sqrt(sumOfSquaresOfDifferences / (values.Count() - 1));
return standardDeviation;
}
public double CalculateConfidenceInterval95(IEnumerable<double> values)
{
double confidenceInterval95 = 1.96 * CalculateStandardDeviation(values) / Math.Sqrt((values.Count() - 1));
return confidenceInterval95;
}
}
}Když máme připravené obě třídy, tak můžeme spustit metodu CreateModel, která nám zobrazí kontrolní (výkonnostní) metriky a model uloží.
new ModelBuilder().CreateModel(datasource: "C:\datasource.tsv", output: "C:\MLModel.zip");K dispozici máme 4 metriky, přesnost, směrodatnou odchylku, interval spolehlivosti a logaritmickou redukci (log loss reduction). Statistika bohužel není moje silná stránka, případného data scientistu tedy pravděpodobně neuspokojím, ale přesto se o interpretaci pokusím.
Přesnost nám říká, na kolik % je model přesný a snaha je se co nejvíce přiblížit 100%. Jedná se o % správných předpovědí. Model nad 90% se dá považovat za dobrý, ale je potřeba brát v úvahu i ostatní metriky. Micro Accuracy zobrazuje přesnost za všechny třídy (pes, kočka, lev) dohromady, ale může být zavádějící, pokud máme nevybalancovaný dataset, například příliš mnoho koček a málo psů. Narozdíl tomu Macro Accuracy nám zobrazuje průměrnou přesnost za jednotlivé třídy zvlášť a hodnota je více vypovídající, pokud máme dataset méně vybalancovaný.
Směrodatná odchylka nám ukazuje, jak moc se liší hodnoty metriky z jednotlivých cross-validation iterací. Čím blíže k 0 tím více se na metriku můžeme spolehnout.
Interval spolehlivosti je obecně rozsah, do kterého hodnota s nějakou pravděpodobností spadá. Jak metriku interpretovat v tomto případě si nejsem úplně jistý, ale asi bych jí interpretoval následovně: Na uvedenou hodnotu metriky se dá spolehnout z 95%, pokud vezmeme v úvahu uvedený % rozsah. Předpokládám tedy, že čím menší rozsah tím lépe. Předpoklad jsem otestoval tak, že jsem zvyšoval počet obrázků a rozsah se zmenšoval.
Logaritmická redukce je metrika, kterou je těžké interpretovat, protože neznáme maximální hodnotu. Můžeme jí ale použít pro porovnání více modelů mezi sebou a důležité je, že čím menší hodnota, tím lepší.

Příprava pro spuštění modelu
Abychom mohli model použít, musíme vytvořit další třídu, která bude umět s modelem pracovat. Tu můžeme vložit buď do stejného projektu, ve kterém jsme model trénovali nebo do jiného projektu, ve kterém chceme model používat, tím může být například i webová stránka. Třída má jedinou veřejnou metodu Predict s parametrem pro vložení obrázku, který chceme rozpoznat a parametrem pro určení cesty k modelu.
ConsumeModel.cs// This file was auto-generated by ML.NET Model Builder.
using Microsoft.ML;
using Microsoft.ML.Data;
using System;
using System.Collections.Generic;
using System.Linq;
namespace ImageRecognition
{
public class ConsumeModel
{
// For more info on consuming ML.NET models, visit https://aka.ms/model-builder-consume
// Method for consuming model in your app
public static ModelOutput Predict(ModelInput input, string modelPath)
{
// Create new MLContext
MLContext context = new MLContext();
// Load model & create prediction engine
ITransformer model = context.Model.Load(modelPath, out _);
var predictionEngine = context.Model.CreatePredictionEngine<ModelInput, ModelOutput>(model);
// Use model to make prediction on input data
ModelOutput result = predictionEngine.Predict(input);
// Show score of each area ordered by score desc
var scoreEntries = GetScoresWithLabelsSorted(predictionEngine.OutputSchema, "Score", result.Score);
foreach (var scoreEntry in scoreEntries)
{
Console.WriteLine($"Area: {scoreEntry.Key} Score: {scoreEntry.Value * 100}%");
}
return result;
}
private static Dictionary<string, float> GetScoresWithLabelsSorted(DataViewSchema schema, string name, float[] scores)
{
Dictionary<string, float> result = new Dictionary<string, float>();
var column = schema.GetColumnOrNull(name);
var slotNames = new VBuffer<ReadOnlyMemory<char>>();
column.Value.GetSlotNames(ref slotNames);
var names = new string[slotNames.Length];
var num = 0;
foreach (var denseValue in slotNames.DenseValues())
{
result.Add(denseValue.ToString(), scores[num++]);
}
return result.OrderByDescending(c => c.Value).ToDictionary(i => i.Key, i => i.Value);
}
}
}Výsledek
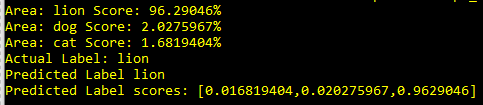
Nyní již máme vše připravené a můžeme model spustit a vyzkoušet ho na novém obrázku, který nebyl v testovacím datasetu. Zavoláme ConsumeModel a jako parametr vložíme cestu k modelu, který již máme vytvořený z předchozí části a cestu k obrázku, který chceme nechat rozpoznat.
var input = new ModelInput
{
Label = "lion",
ImageSource = "C:\images\lion4.jpg"
};
ModelOutput result = ConsumeModel.Predict(input);
Console.WriteLine($"Actual Label: {input.Label} " +
$"\nPredicted Label {result.Prediction} " +
$"\nPredicted Label scores: [{String.Join(",", result.Score)}]");Na obrázku byl lev a model nám lva, s pravděpodobností 96%, správně rozpoznal, hurá :-)