Databázový vývoj pomocí SSDT
08.08.2022
Slovník
| SQL Server | Databázový server, původně vyvinutý společností Sybase, byl později koupen a dále rozvíjen společností Microsoft. První verze byla vydána v roce 1989 a jedná se o jednu z nejrozšířenějších databází. |
| T-SQL | Transact-SQL je rozšíření jazyka SQL používané v SQL Serveru. Má vlastní syntaxi a funkce, podobně jako PL/SQL od společnosti Oracle. |
| SSDT | SQL Server Data Tools je rozšíření pro Visual Studio, které výrazně usnadňuje vývoj databází pro SQL Server. |
| SSMS | SQL Server Management Studio je databázový klient, který umožňuje připojení k SQL Serveru, správu databází a spouštění T-SQL skriptů. |
| SQL CLR | SQL Common Language Runtime umožňuje spouštět kód napsaný v .NET přímo z T-SQL. |
| Linked Server | Linked Server slouží k tomu, abychom mohli přistupovat k datům z externích zdrojů, například na jiný databázový server nebo OLE DB zdroj. |
| Schema | Schema je buď konkrétní typ databázového objektu, který slouží k seskupování dalších objektů za účelem řízení oprávnění (někdy se používá jako namespace pro lepší organizaci objektů, ale to není doporučená praktika), nebo obecný pojem označující všechny databázové objekty v dané databázi. |
| Trustworthy | Databázová vlastnost, která určuje, zda SQL Server důvěřuje dané databázi. Pokud ano, může například procedura s příznakem "with execute as owner" přistupovat k dalším databázím na stejném serveru na základě oprávnění nastavených v cílových databázích. Propojování databází touto metodou by mělo být používáno pouze v odůvodněných případech, kdy jsou databáze plně pod kontrolou a řešení odpovídá zvolené architektuře. Nastavení vlastnosti Trustworthy ovlivňuje také spouštění CLR a dalších funkcí. Obecně se nedoporučuje nastavovat Trustworthy na hodnotu True. |
| Synonym | Alias pro databázový objekt v jiné databázi. Osvědčilo se mi vytvářet pro reference na objekty v jiných databázích, abych měl na jednom místě přehled o všech databázových závislostech. Synonymy lze také použít pro optimalizaci Entity Framework cross-database dotazů. |
| tSQLt | Open source framework pro vytváření a spouštění databázových testů. SSDT také umožňuje vytvářet testy, ale nenabízí takové možnosti jako tSQLt. tSQLt lze integrovat do SSDT projektu. Další alternativou pro psaní databázových testů je testovací framework xUnit, který se používá pro .NET projekty. V současnosti se doménová logika již běžně neimplementuje do uložených procedur, a proto význam databázových unit testů není tak velký, ale vždy záleží na konkrétním projektu. Databáze může být také pokrytá integračními testy aplikační vrstvy, ale použítí unit testů by mělo mít přednost. |
| DACPAC | Data-tier applications package (DACPAC) je soubor, který obsahuje informace o všech databázových objektech a SSDT ho na pozadí používá pro deployment. Pomocí DACPAC balíčku lze také do SSDT projektu přidat závislost na další databázi. |
Obsah
Úvod
K databázovému vývoji patří verzování, deployment, testování, import počátečních dat, řízení přístupů a podobně. Pravděpodobně budeme potřebovat několik prostředí, například vývojové a produkční, a budeme mít minimálně dvě databáze. Spravovat databáze pouze pomocí SQL příkazů by bylo náročné a náchylné na chyby, proto je velmi vhodné zvolit tooling, který nám pomůže zautomatizovat nejčastější operace.
Pokud vyvíjíme aplikaci nebo se pouštíme do datově analytického projektu a máme možnost využít SQL Server, tak můžeme zvolit SSDT nástroje. Další možností je použít databázové migrace, které jsou například součástí EF Core ORM frameworku a umožňují nám pracovat i s jinýmy databázovými systémy.
SSDT a databázové migrace fungují velmi odlišně. Je potřeba zvážit, kterou technologii použít, případně zvolit i jejich kombinaci. V tomto článku se budu věnovat databázovému projektu ve Visual Studiu, nikoliv rozšířením SSAS nebo SSIS, které jsou také součástí SSDT.
Příprava prostředí
Pro databázový vývoj budeme potřebovat databázový server a databázového klienta. Server nainstalujeme do Docker kontejneru (SQL Server od verze 2017 podporuje instalaci na Linux), a jako klienta použijeme SSMS. K databázi se však lze připojit i přímo z Visual Studia. Ve Visual Studiu vytvoříme databázový projekt, který bude obsahovat nastavení databáze, všechny databázové objekty a SQL skripty. Místo Docker kontejneru lze SQL Server nainstalovat i klasicky pomocí instalátoru. Vše doporučuji instalovat v angličtině, protože se pak snadněji řeší případné problémy.
Pokud zvolíme Visual Studio Community edici, SQL Server Express edici a Docker personal licenci, získáme profesionální prostředí zdarma, které můžeme s omezením používat i pro komnerční účely. Například Visual Studio má velmi volnou licenci, co se týká databázového vývoje. 🙂
Instalace Visual Studia
Pokud máte Visual Studio již nainstalované, zkontrolujte v Tools > Get Tools and Features..., že máte nainstalovanou podporu pro SSDT. V případě nové instalace nezapomeňte tuto podporu zaškrtnout.


Instalace serveru
Nainstalujeme Docker a spustíme následující příkazy v příkazové řádce nebo PowerShellu. Nejprve stáhneme SQL Server image, následně spustíme instalaci, při které zvolíme Express edici a nastavíme heslo pro administrátora serveru (heslo musí splňovat požadavky na komplexitu). Na závěr spustíme kontejner, který můžeme pojmenovat libovolně (například MSSQL2019)
docker pull mcr.microsoft.com/mssql/server
docker run --name MSSQL2019 -e "ACCEPT_EULA=Y" -e "SA_PASSWORD=Pa$$w0rd" -e "MSSQL_PID=Express" -p 1433:1433 -d mcr.microsoft.com/mssql/server
docker start MSSQL2019Připojení k serveru
Po instalaci a spuštění SQL Serveru se můžeme přihlásit pomocí SSMS. Adresa serveru je localhost a heslo jsme nastavili při vytváření Docker kontejneru.
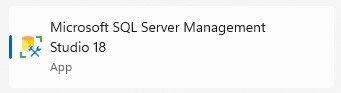
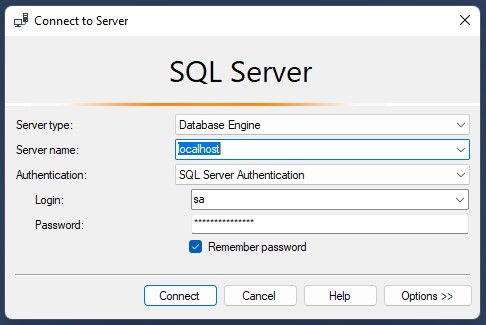
Vytvoření databáze
Po připojení k serveru vytvoříme databázi, tu můžeme vytvořit pomocí průvodce.
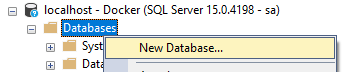
Databázový projekt
Nyní, když máme připravenou databázi, můžeme začít prozkoumávat SSDT.Založení projektu
Spustíme Visual Studio a založíme nový projekt

Import z existující databáze
Pokud bychom měli existující databázi, která obsahuje databázové objekty, můžeme ji do našeho projektu importovat.
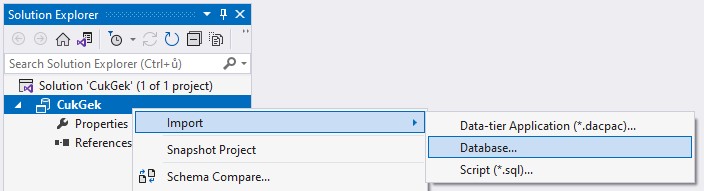
Struktura projektu
Na začátku projektu je dobré si zvolit způsob organizace souborů. Můžeme se například řídit výchozí strukturou schema/object type, která vypadá následovně (několik objektů jsem již vytvořil):
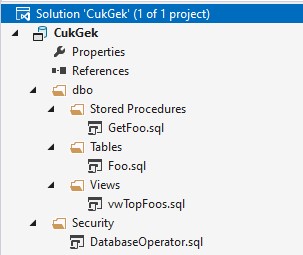
Deployment
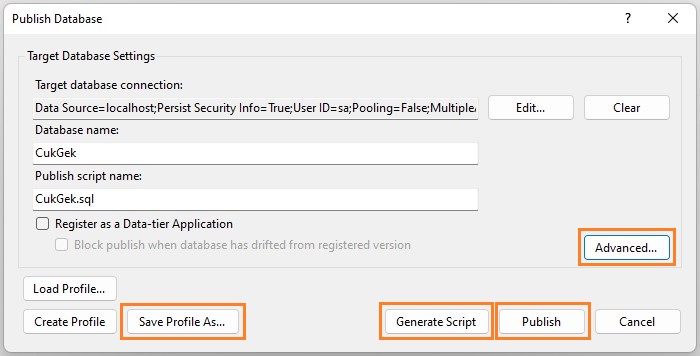
V okamžiku, kdy máme vytvořené tabulky, procedury, funkce a další objekty, a chceme je nasadit na cílový databázový server, můžeme použít tzv. publish profil (Projekt > Publish...), který provede buď přímo aktualizaci cílové databáze podle nastavení databázového projektu, nebo si můžeme uložit aktualizační skript do samostatného souboru.
Například pokud v projektu vytvoříme novou tabulku, bude tato tabulka při aktualizaci vytvořena i v databázi. Pokud by při nasazování došlo k tzv. breaking změně, která by mohla způsobit ztrátu dat, takovou aktualizaci musíme explicitně povolit
Databázové vlastnosti
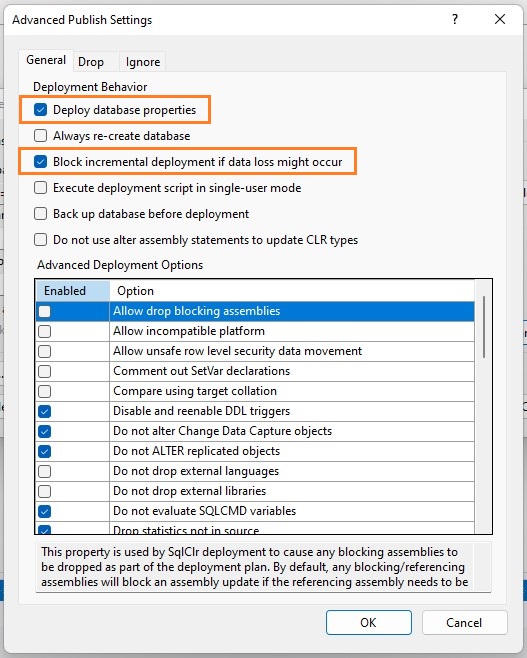
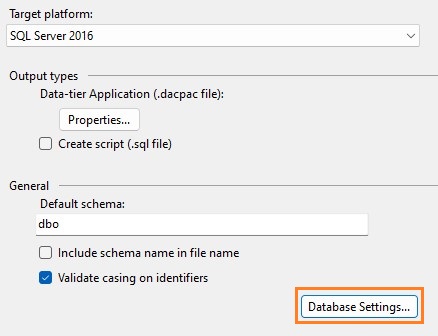
V Projekt > Properties je možné nastavit mnoho vlastností, které ve výchozím stavu přepisují nastavení cílové databáze. Je důležité se domluvit s administrátorem serveru a zjistit, jaké databázové vlastnosti chceme mít nastavené a zda je spravovat v projektu. Z mojí zkušenosti je dobré dávat pozor především na následující vlastnosti:
- Target platform
- Database collation
- Compatibility level
- Trustworthy
Scripty
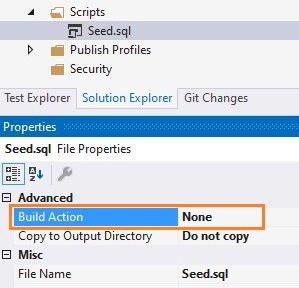
V projektu můžeme mít uložené i scripty, které slouží pouze pro servisní zásahy nebo jednorázové operace. Takové scripty je třeba vyloučit z buildu. V případě potřeby můžeme pomocí vlastnosti build action vytvořit také tzv. pre-deployment a post-deployment scripty, které se spustí před nebo po publikaci.
SQL CLR
Máme možnost napsat kód v jazyce C# a volat ho jako funkci nebo proceduru z T-SQL. SSDT vytváření SQL CLR významně zjednodušuje. Například si můžeme vytvořit funkci, která zjistí, zda se jedná o přestupný rok:
using System;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
public partial class UserDefinedFunctions
{
[SqlFunction]
public static SqlBoolean IsLeapYear(int year)
{
return DateTime.IsLeapYear(year);
}
}if ((select value_in_use from sys.configurations where [name] = 'clr enabled') = 0)
begin
EXEC sp_configure 'clr enabled', 1;
RECONFIGURE;
endEXEC sp_configure 'show advanced options', 1;
RECONFIGURE;
EXEC sp_configure 'clr strict security', 0;
RECONFIGURE;Potom nám už nic nebrání naší C# funkci použít následovně:
select dbo.IsLeapYear(2022)Schema compare
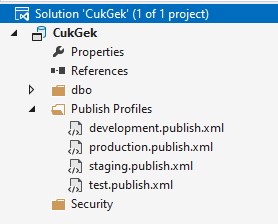
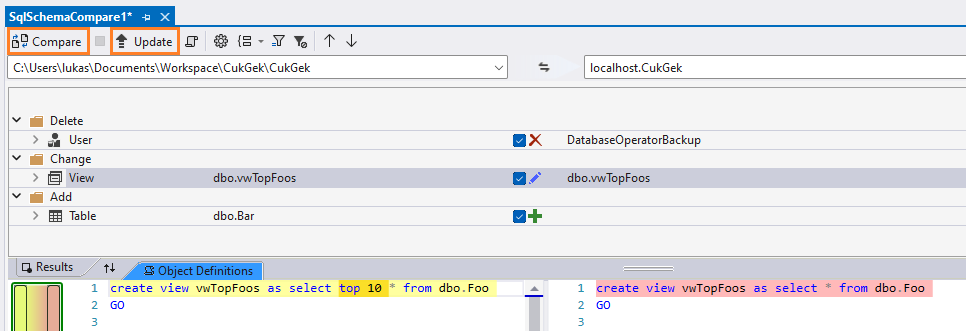
Další zajímavou funkcí je porovnání databáze, projektu nebo DACPAC balíčku. Funkci vyvoláme ze Solution Exploreru pomocí volby Projekt > Schema Compare. Pokud jsme například dělali změny přímo v cílové databázi, můžeme zkontrolovat, zda je náš projekt aktuální, nebo jestli v databázi není něco navíc. Na obrázku například vidíme, že nám v projektu chybí uživatel DatabaseOperatorBackup, máme nepublikovanou novou tabulku dbo.Bar, a liší se nám view dbo.vwTopFoos. Pokud bychom se rozhodli pro automatickou aktualizaci, musíme být velmi opatrní a mít jasno v tom, co jsme označili za zdroj a cíl.
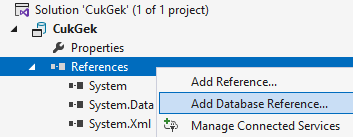
Reference na další databáze
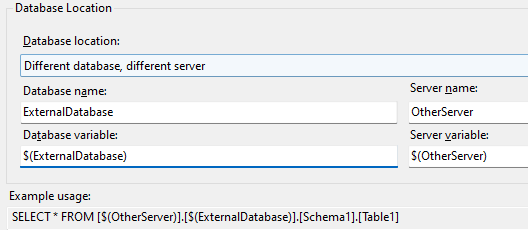
Do projektu můžeme přidat odkaz na jiný databázový projekt, systémovou databázi (msdb nebo master) nebo DACPAC balíček. Při přidávání zvolíme, kde se databáze nachází, a tím se nám vytvoří proměnné, které můžeme použít kdekoliv ve scriptech. Hodnota proměnných se pak nastavuje v publish profilu. Při používání externích databází doporučuji vytvářet odkazy na vzdálené tabulky jako synonyma, protože pak existuje přehled o závislostech na jednom místě. Synonyma se také hodí, pokud chceme mít pouze jeden databázový kontext v Entity Frameworku a vyhnout se distribuovaným transakcím, pokud to není nutné. Nevýhodou v takovém případě je, že přijdeme o IntelliSense nápovědu.
Závěr
V tomto článku jsme si nainstalovali prostředí pro databázový vývoj a prošli jsme hlavní funkce databázového projektu ve Visual Studiu. Teď už stačí jen navrhovat a kódovat. 🙂 Pokud máte zkušenosti s databázovým vývojem ve Visual Studiu, dejte vědět v komentářích. 😉